Prediction of TIRF MT semantics/instances
This guide provides detailed instructions to perform fully automatic microtubule segmentation on all of your images using our most up-to-date model.
TARDIS can predict fully automatic microtubules as semantic labels, or instances [track, or labels].
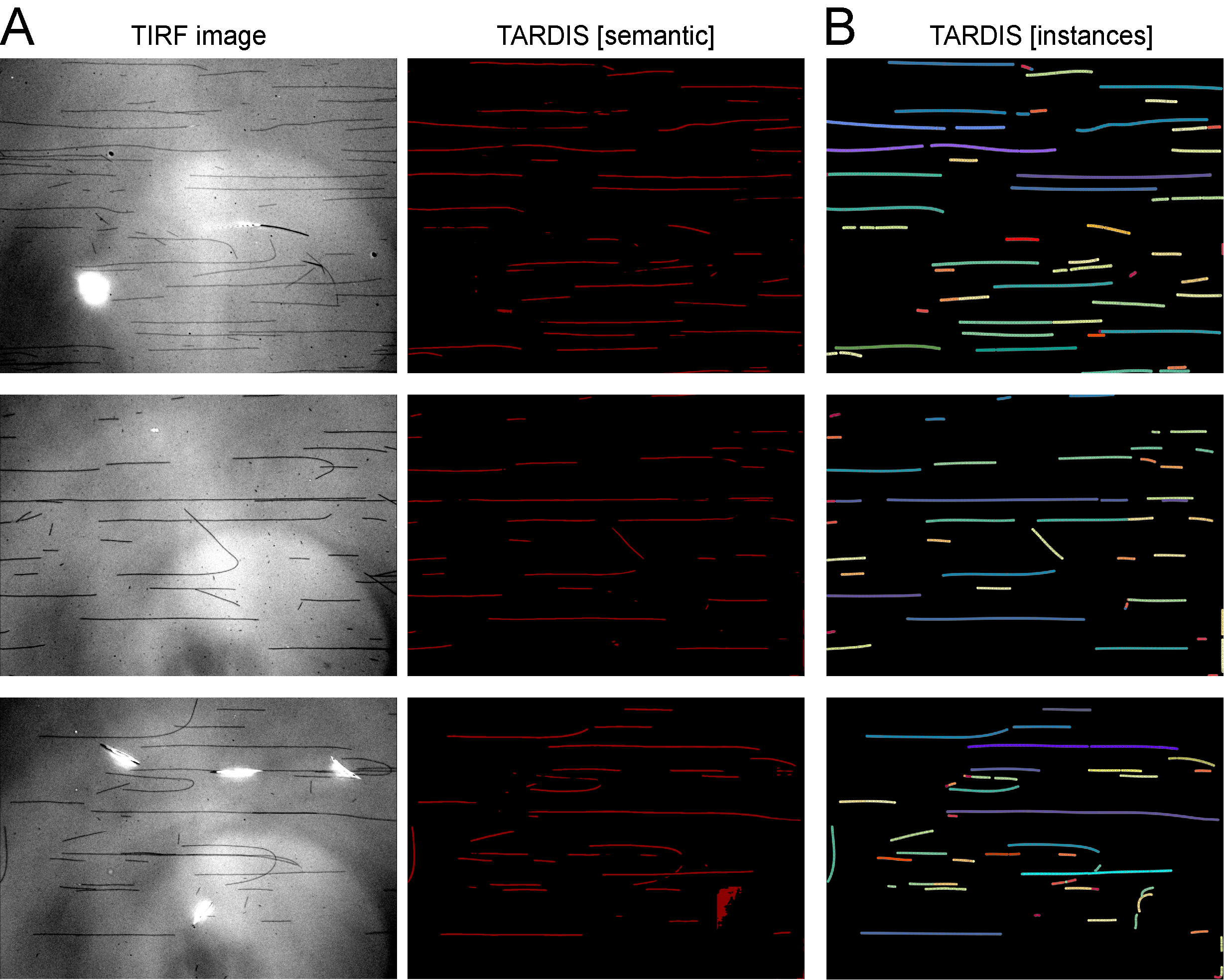
Data source: RNDr. Cyril Bařinka, Ph.D, Biocev
Example of segmented images with indicated predicted semantic binary segmentation and individual instances represented as tracks of different colors.
TARDIS Workflow
Prepare a folder with data
Predict microtubule segmentation
(Optional) Advance prediction setting
Preparation
Simply store all your images in one folder. TARDIS will recognize all image file with the extension [.tif, .tiff, .rec, .map, .mrc, .am, .npy, .nd2].
Tip: In the case of REC/MAP/MRC files try to make sure that files have embedded in the header pixel size information.
Prediction
(Optional) Type the following to check if TARDIS is working properly.
Tips: If any error occurs, try using our troubleshooting chapter.
tardis
This will display the TARDIS interface and show available options.
Semantic/Instance segmentation:
For the semantic prediction, you only need to type:
tardis_mt_tirf -dir <path-to-your-images> -out <output_type>
TARDIS will save predictions in the default folder Prediction located in
the folder with your data.
Running this will segment all images in the indicated path. Predicted output
will be store in file format indicated in -out <output_type> [see all -out options].
You can also segment individual file by replacing -dir with file not a folder location.
For example:
tardis_mt_tirf -dir <path-to-your-images> -out tif_None
Will perform only semantic segmentation and save the output file as a tirf file.
tardis_mt_tirf -dir <path-to-your-images> -out None_csv
Will perform only instance segmentation and save the output file as .csv spatial graph file with data structure as [Microtubule ID x X x Y x Z]
tardis_mt_tirf -dir <path-to-your-images> -out tif_csv
Will perform semantic and instance segmentation and save the output file as .tirf and .csv spatial graph files.
- Additionally, TARIDS will output analysis for all predicted files, including:
Length
Curvature
Tortuosity
Avg. intensity
Avg. intensity over length
Sum. intensity
Sum. intensity over length
Tips: As a final product of TARDIS instance segmentation for microtubules, TARDIS produces two files.
The first file with _instances.csv extension contains all predicted microtubules. The second file
with _instances_filter.csv extension contains filter microtubules based on length and curvature [-fl or --filter_by_length: Minimum microtubule length].
Advance usage:
Below you can find all available arguments you can use with tardis_mt,
with the explanation for their functionality:
-diror--path: Directory path with all images for TARDIS prediction.default: Current command line directory.
-msor--mask: Define if your input is a binary mask with a pre-segmented microtubules.Example: You can set this argument to
-ms Trueif you have already segmented microtubules and you only want to segment instances.default: False
Allowed options: True, False
-pxor--correct_px: Overwrite pixel value.Example: You can set this argument to
-px Trueif you want to overwrite the pixel size value that is being recognized by TARDIS.default: False
Allowed options: True, False
-chor--checkpoint: Directories to pre-train models.Example: If you fine-tuned TARDIS on your data you can indicate here file directories for semantic and instance model. To do this type your directory as follow:
-ch <semantic-model-directory>|<instance-model-directory>. For example, if you want to pass only semantic model type:-ch <semantic-model-directory>|None.default: None|None
-outor--output_format: Type of output files.Example: Output format argument is compose of two elements
-out <format>_<format>. The first output format is the semantic mask, which can be of type: None [no output], am [Amira], mrc, or tif. The second output is predicted instances of detected objects, which can be of type: output as amSG [Amira spatial graph], mrc [mrc instance mask], tif [tif instance mask], csv coordinate file [ID, X, Y, Z], stl [mesh grid], or None [no instance prediction].default: mrc_csv
Allowed options: am_None, mrc_None, tif_None, None_am, am_am, mrc_am, tif_am, None_amSG, am_amSG, mrc_amSG, tif_amSG, None_mrc, am_mrc, mrc_mrc, tif_mrc, None_tif, am_tif, mrc_tif, tif_tif, None_csv, am_csv, mrc_csv, tif_csv, None_stl, am_stl, mrc_stl, tif_stl
-psor--patch_size: Window size used for prediction.Example: This will break images into smaller patches with 25% overlap. Smaller values than 128 consume less GPU, but also may lead to worse segmentation results!
default: 128
Allowed options: 32, 64, 96, 128, 256, 512
-rtor--rotate: Predict the image 4 times rotating it each time by 90 degrees.Example: If
-rt True, during semantic prediction images is rotate 4x by 90 degrees. This will increase prediction time 4 times. However, it usually will result in cleaner output.default: True
Allowed options: True, False
-ctor--cnn_threshold: Threshold used for semantic prediction.Example: Higher value then
-ct 0.25will lead to a reduction in noise and microtubule prediction recall. A lower value will increase microtubules prediction recall but may lead to increased noise.default: 0.25
Allowed options: Float value between 0.0 and 1.0
-dtor--dist_threshold: Threshold used for instance prediction.Example: Higher value then
-dt 0.5will lower number of the predicted instances, a lower value will increase the number of predicted instances.default: 0.5
Allowed options: Float value between 0.0 and 1.0
-pvor--points_in_patch: Window size used for instance prediction.- Example: This value indicates the maximum number of points that could be
found in each point cloud cropped view. Essentially, this will lead to dividing a point cloud into smaller overlapping areas that would be segmented individually and then stitched and predicted together. Tips: 1000 points per crop requires ~12 GB of GPU memory. For GPUs with smaller amounts of GPU memory, you can use lower numbers 500 or 800. A higher number will always lead to faster inference, and may slightly improve segmentation.
default: 1000
Allowed options: Int value between 250 and 5000.
-flor--filter_by_length: Minimum microtubule lengthExample: Filtering parameters for microtubules, defining maximum microtubule length in Angstrom. All filaments shorter then this length will be deleted.
default: 1000
-csor--connect_splines: Threshold distance between two microtubulesExample: To address the issue where microtubules are mistakenly identified as two different filaments, we use a filtering technique. This involves identifying the direction each filament end points towards and then linking any filaments that are facing the same direction and are within a certain distance from each other, measured in angstroms. This distance threshold determines how far apart two microtubules can be, while still being considered as a single unit if they are oriented in the same direction.
default: 2500
-ccor--connect_cylinder: Microtubule thickens in AngstromExample: To minimize false positives when linking microtubules, we limit the search area to a cylindrical radius specified in angstroms. For each spline, we find the direction the filament end is pointing in and look for another filament that is oriented in the same direction. The ends of these filaments must be located within this cylinder to be considered connected.
default: 250
-dvor--device: Define which device to use for inference.Example: You can use
-dv gputo use the first available gpu on your system. You can also specify the exact GPU device with the number-dv 0,-dv 1, etc. where 0 is always the default GPU. You can also use-dv cputo perform inference only on the CPU.default: 0
Allowed options: cpu, gpu, 0, 1, 2, 3, etc.
-dbor--debug: Enable debugging mode.Example: Debugging mode saves all intermediate files allowing for debugging any errors. Use only as a developer or if specifically asked for by the developer.
default: False
Allowed options: True, False